论文精读 Score-based Generative Model
摘要
基于分数的生成模型是与 DDPM 不同的一个分支。主要介绍宋飏老师提出的 NCSN (Noise Conditional Score Network),模型主要基于分数匹配和朗之万动力学采样,以及训练时的加噪策略。
论文:Generative Modeling by Estimating Gradients of the Data Distribution
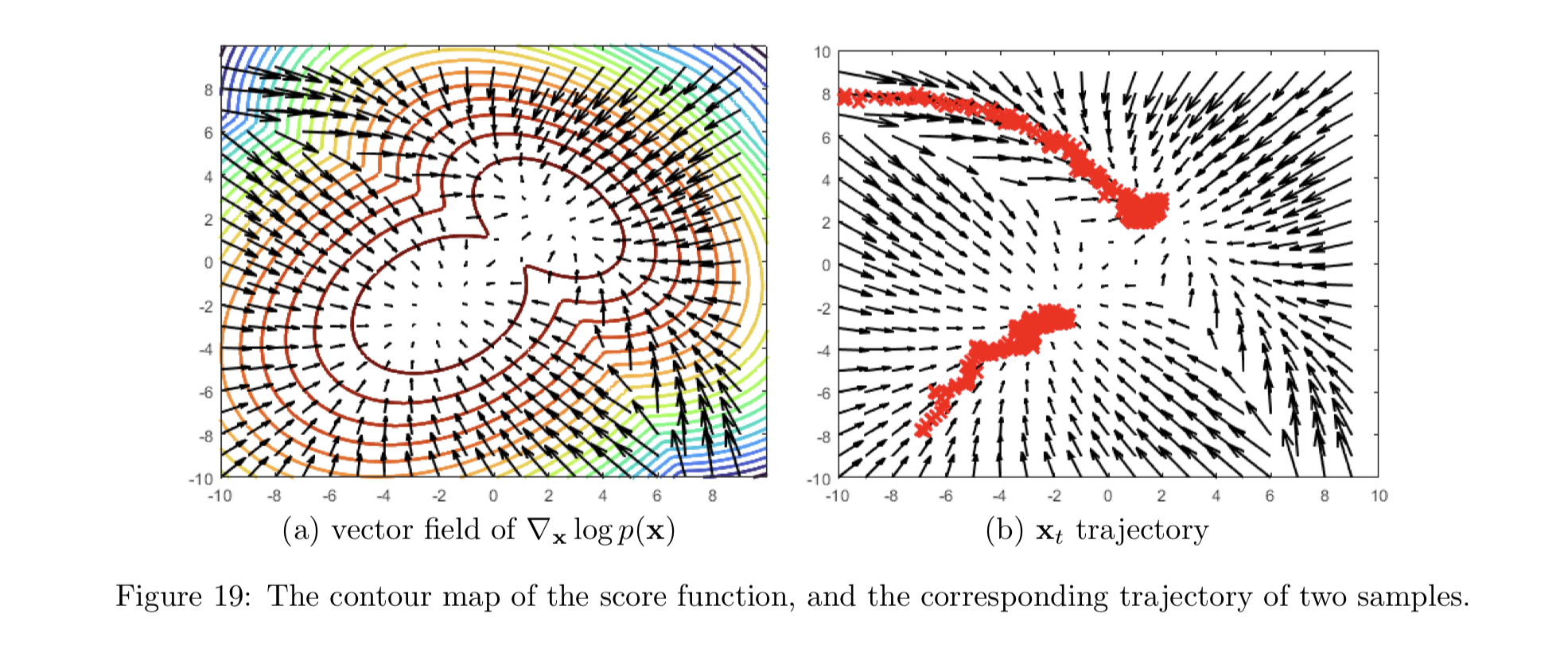
分数函数及郎之万动力学采样
首先定义 Stein Score:$s\theta(x)= \nabla_x \log p\theta (x)
注意 Stein 分数和最大似然的区别。Stein 分数是对 x 求导,而最大似然 $sx(\theta)= \nabla\theta \log p_\theta (x)
\theta \theta \theta$ 最大概率的取值。
为了从分数表征的分布
(降噪)分数匹配
为了对分数函数进行优化,显然目标函数可以直接定义为网络估计出来的分数
如果知道真实分布
降噪分数匹配方法中,首先给原始数据添加随机噪声

对上面 85 式使用蒙特卡洛方法取样计算其均值即可计算损失函数。下图所示的模型结构展示了这一过程。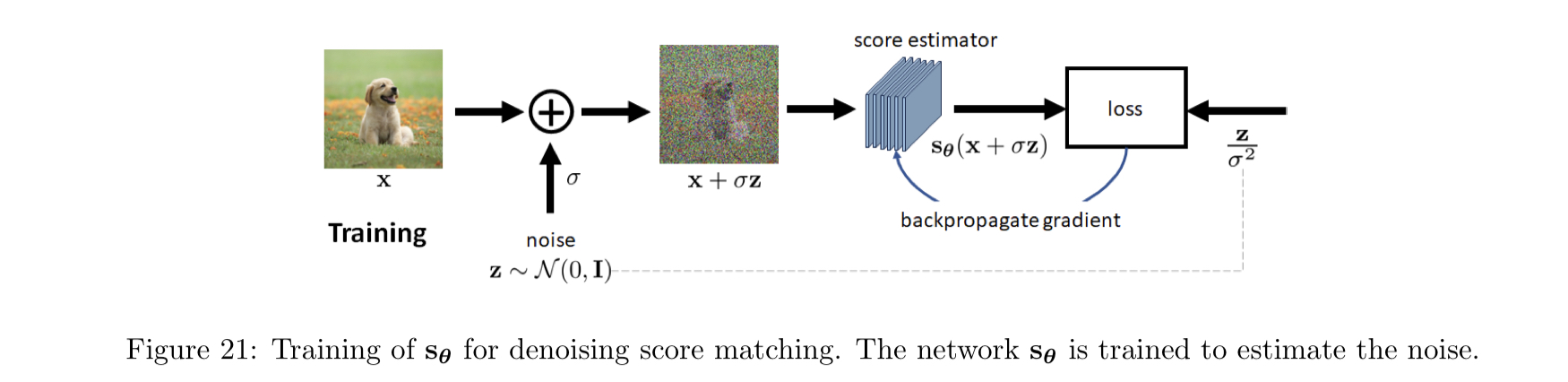
面临的困难
- 数据样本集中在嵌入高维空间的低维流形上。说人话就是样本的各个维度并不完全互相独立,即列不满秩。对于
维的图像来说,实际互相独立的可能只有 2000 个维度,反映到分数匹配上就是偏导数理论上有任意解,训练不稳定。 - 低概率密度区域的估计不准确。本质上是观测样本数量不足的问题,概率密度低的地方其样本的产生概率也低,此时分数匹配方法对这些区域的拟合和学习就不足,导致预测不准确。

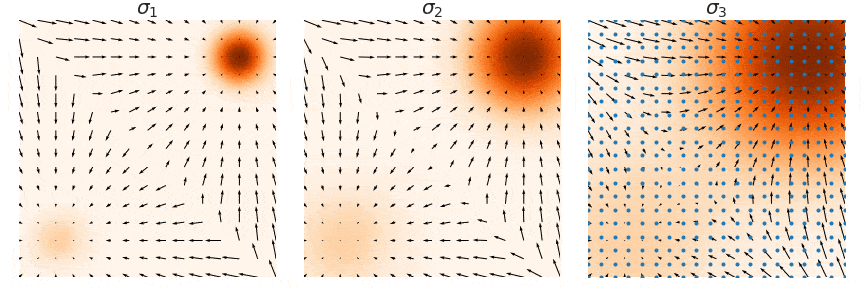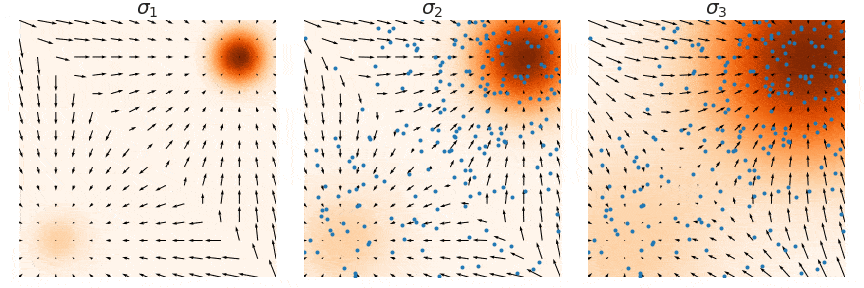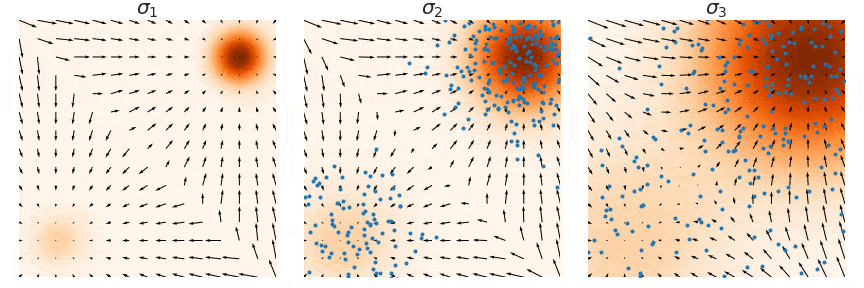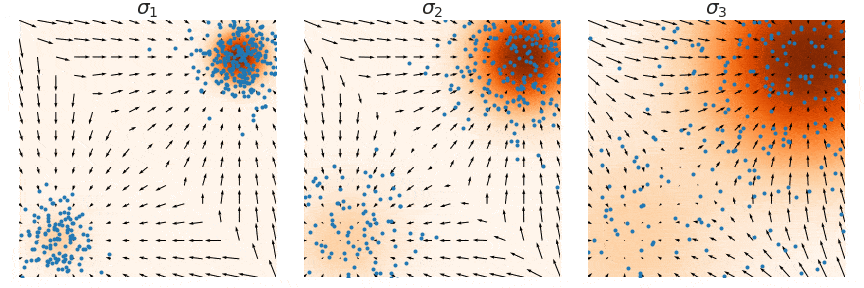
- 朗之万采样的缺陷。以高斯混合分布
为例,朗之万采样只能采样到概率密度极大位置,但是不同的概率密度的极大点亦有大小区别,也就是丢失了系数 、 的信息。另外存在迭代速度慢的问题。
噪声条件分数网络
为了解决上述三个问题,NCSN 通过给数据增加噪声扰动的方式,一方面破坏了原来数据各个维度的相关性,另一方面扩大了数据分布高密度区域的面积。在数据分布上加上高斯噪声后,均值保持不变,方差变大,这会把高密度区域的面积增大,使得更多区域的分数函数被准确估计出来。
具体来说,定义了一个噪声序列,递进式地添加 L 个不同强度的噪声。即 ${\sigmai}{i=1}^L
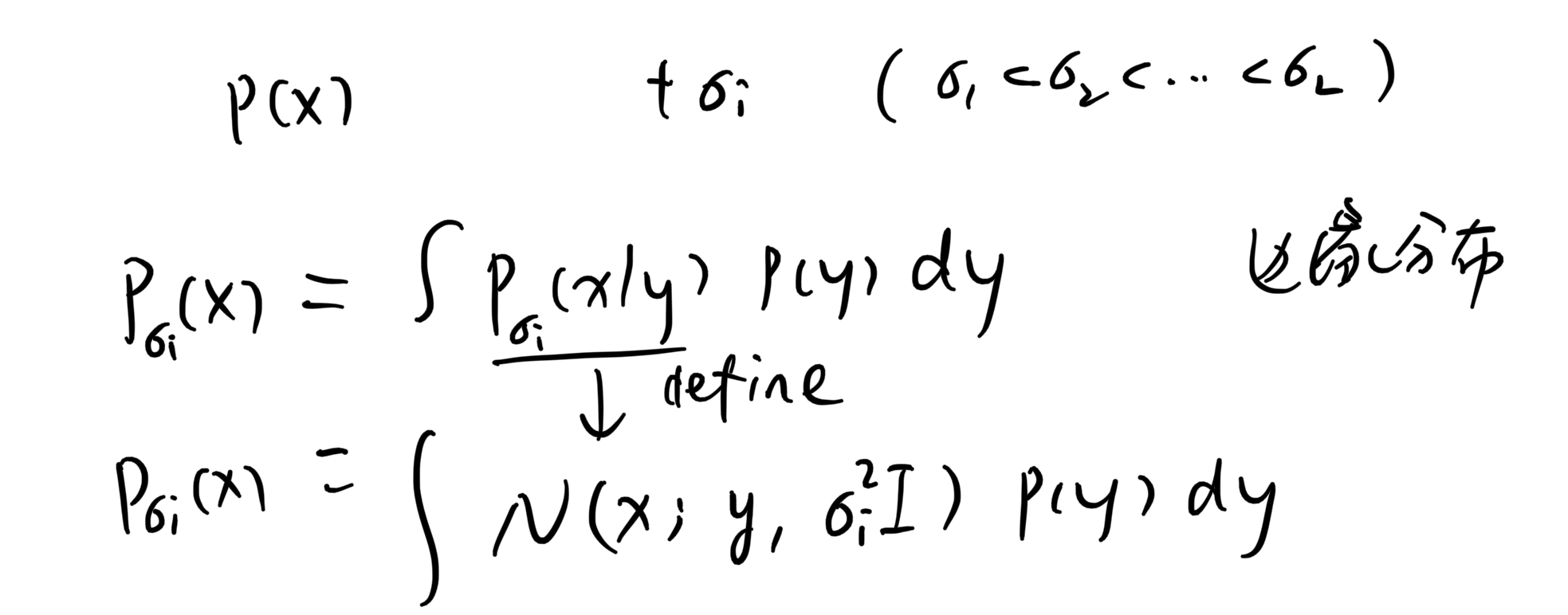
注意:采样时只需取
,然后 ,如此得到的 即满足加噪后的分布。
对于每一个
训练得到分数估计值